Big Data Dashboards mit Databricks
Einführung
“It’s all about data” - diese Aussage wird immer mehr zur Realität. Daten sind das Gold des neuen, digitalen Zeitalters. Umso relevanter werden Infrastrukturen und Plattformen, über die man effizient auch größte Datenmengen verarbeiten und visualisieren kann. Denn nur wer die Daten versteht, sie visualisieren und kritisch hinterfragen kann, ist in der Lage, aus ihnen das größtmögliche Wissen zu generieren.
Databricks
Was ist Databricks?
Databricks ist eine cloudbasierte Analyseplattform, die, aufbauend auf die Open-Source-Technologie Apache Spark, Anwenderinnen und Anwendern ermöglicht, größte Datenmengen zu verarbeiten, zu transformieren und zu analysieren. Neben klassischen ETL-Tasks können Machine Learning Algorithmen auch auf Big Data angewendet werden, sodass Databricks als ideale Plattform für die Analyse von Big Data genutzt werden kann. In Azure ist Databricks mit der Ressoruce Azure Databricks integriert, sodass die Vorteile von Databricks auch in Azure-Workflows verwendet werden können.
Die Rechenoperationen in Databricks werden auf sog. Spark-Clustern ausgeführt, also Clusterpools, die aus einer Master- und mehreren Worker-VMs bestehen. Die effiziente Verteilung der Aufgaben auf die Worker, die Spark automatisiert vornimmt, ermöglicht, dass die Big Data Operationen beliebig skaliert werden können.
Anbindung von Daten
Databricks kann mit verschiedensten Datenquellen verbunden werden, beispielsweise Azure Blob Storages, Azure Data Lakes, Azure Cosmos DB oder SQL-Databases. Die Zugangsdaten müssen für einen sicheren Zugang in einem Azure Key-Vault hinterlegt sein, der mit Databricks über Geheimnisbereiche verknüpft werden kann. Eine Beschreibung über die Anbindung verschiedenster Datenquellen findet man in der Dokumentation zu Azure Databricks
Implementation in Notebooks
Die Entwicklung in Databricks geschieht über sog. Notebooks.
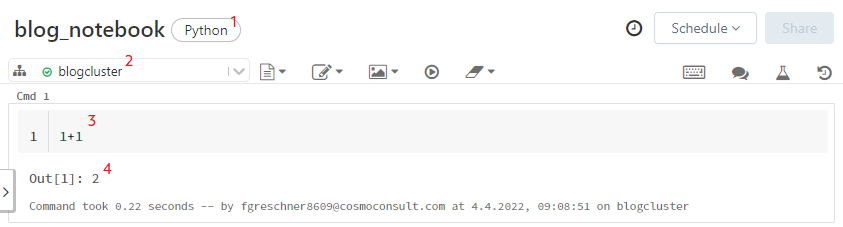
Abb. 1: Notebooks in Databricks
Jedes Notebook muss an einen Compute-Cluster angehängt sein (siehe 2 in Abb. 1), der die Ausführung des Codes übernimmt. Ein Compute-Cluster besteht hierbei aus einem Driver und mehreren Workern, wobei sowohl Driver als auch Worker jeweils kleine virtuelle Maschinen sind. Während die meisten Implementierungsaufgaben nur auf dem Driver ausgeführt werden, können beispielsweise Spark-Anwendungen auf den gesamten Pool verteilt werden.
Jedes Notebook besteht aus mehreren Zellen, wobei zu jeder Input-Zelle (siehe 3 in Abb. 1) eine Output-Zelle (siehe 4 in Abb. 1) gehört.
Für jedes Notebook muss eine Standardsprache angegeben werden (siehe 1 in Abb. 1). Zur Auswahl stehen hierbei Python, Scala, SQL und R. Die Standardsprache beschreibt dabei, welcher Interpreter bei der Ausführung der Zelle standardmäßig verwendet wird. Es ist möglich, einzelne Zellen durch sog. Magic-Sprachbefehle die Sprache einer einzelnen Zelle zu ändern. Mögliche Magic-Befehle sind beispielsweise %python für Python, %sql für SQL, %rfür R, %scala für Scala oder %md für Markdown, also Textzellen. Auf diese Weise können verschiedene Sprachen in Notebooks gleichzeitig verwendet werden, siehe Abb. 2.
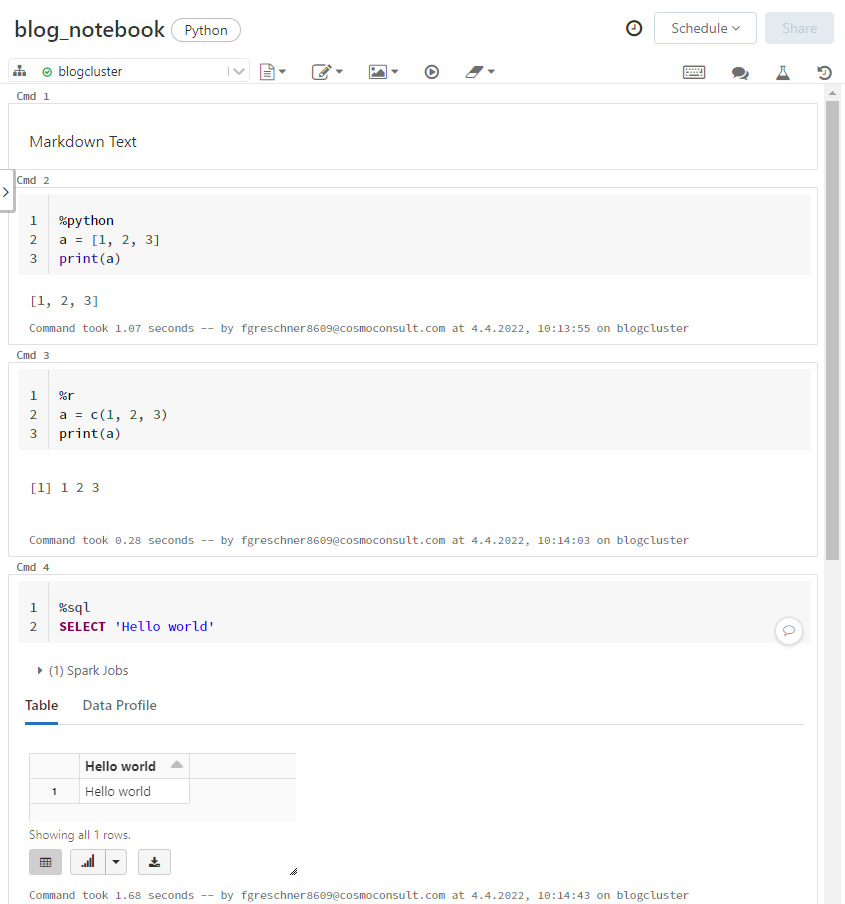
Abb. 2: Verschiedene Sprachen in Notebooks
Neben den üblichen Ausgaben in Output-Zellen können Data Frames mit der display()-Funktion in integrierten Grafiken dargestellt werden (siehe 1 in Abb. 3). Nach Klick auf das Grafik-Symbol (siehe 2 in Abb. 3) wird eine Standard-Grafik angezeigt, die durch Klick auf “Plot Options” (siehe 3 in Abb. 3) individualisiert werden kann. Diese Grafiken können später in ein Dashboard eingebunden werden.
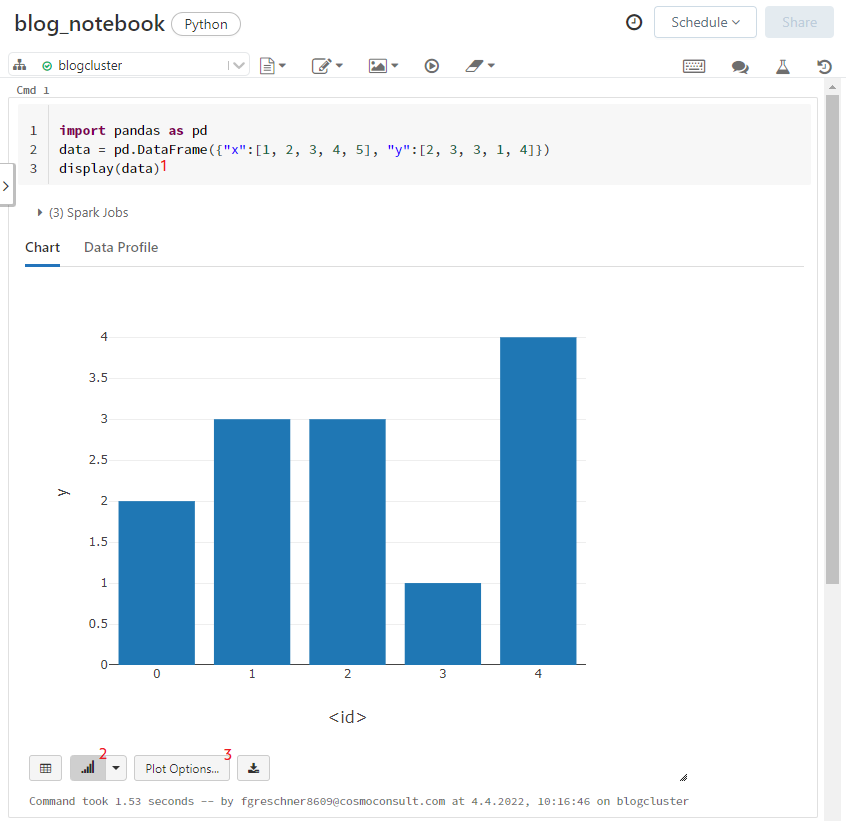
Abb. 3: Grafiken in Databricks Notebooks
Parametrisierung von Notebooks
Databricks Notebooks sind insbesondere dafür geeignet, in übergeordneten Pipelines wie Databricks Pipelines oder Azure Synapse Pipelines eingebunden zu werden. Aus diesem Grund kann es notwendig sein, bestimmte Parameter von außen übergeben zu können. Diese Funktion ist in Databricks Notebooks durch sog. widgets möglich.
Durch den Befehl dbutils.widgets.text("Input1", "Wert") kann beispielsweise ein Parameter Input1 mit dem Standardwert "Wert" angelegt werden, der mit dem Befehl dbutils.widgets.get("Input1") abgerufen und benutzt werden kann, siehe Abb. 4.
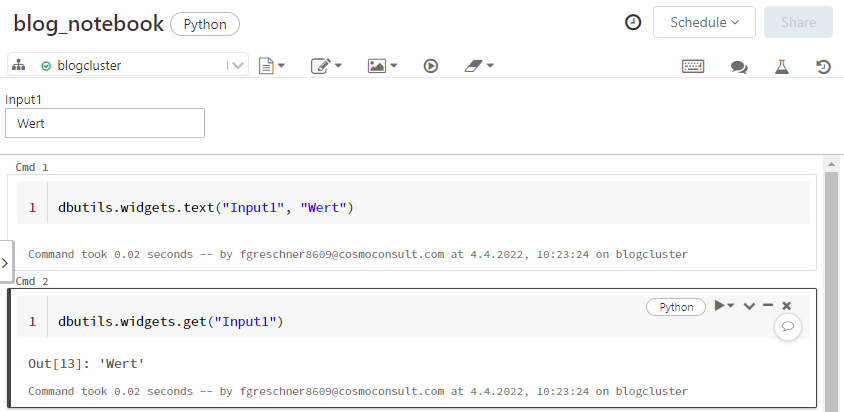
Abb. 4: Parameter in Databricks Notebooks
Dashboards in Databricks
Im vorherigen Abschnitt wurde beschrieben, dass in Output-Zellen diverse Möglichkeiten existieren, die Ergebnisse einzelner Abfragen zu visualisieren. Dashboards bieten die Möglichkeit, diese Visualisierungen, also die tabellarische oder grafische Darstellung von Ergebnissen, sowie Markdown Zellen in einer interaktiven Oberfläche bereit zu stellen. Dabei werden Dashboards auf Notebooks aufgesetzt, sodass nur ein geringer Zusatzaufwand nötig ist. Wie Dashboards aus einem Notebook entwickelt werden und worauf man achten muss, wird in diesem Abschnitt beschrieben.
Entwicklung von Dashboards
Dashboards “leben” auf einzelnen Notebooks. Um ein Dashboard erstellen zu können, muss es zunächst angelegt werden (siehe 1 und 2 in Abb. 5).

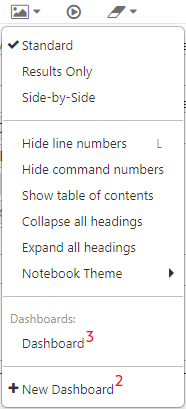
Abb. 5: Anlegen eines Dashboards
Nach dem Anlegen können sämtliche bereits im Notebooks verfügbare Output-Zellen sowie Markdown Zellen zum Dashboard hinzugefügt werden (siehe 1 und 2 in Abb. 6).
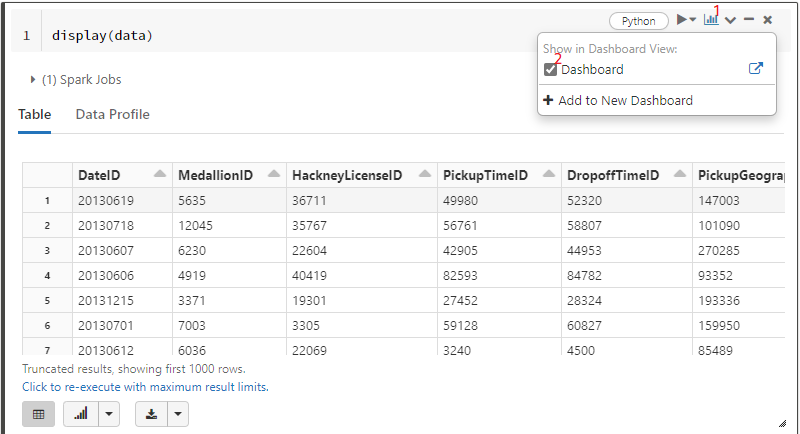
Abb. 6: Hinzufügen eines Outputs zu einem Dashboard
Zusätzlich zu den Output-Zellen werden Parameter, die über dbutils.widgets hinzugefügt wurden, im Dashboard angezeigt (siehe 1 in Abb. 7). Nachdem alle benötigten Zellen inkl. Markdown Zellen im Dashboard zur Verfügung gestellt worden sind, kann das Dashboard designed werden. Dazu muss auf das Dashboard gewechselt werden (siehe 3 in Abb. 5).
Im Dashboard Editor können neben einigen Einstellungen zum Dashboard (siehe 3 in Abb. 7) die verschiedenen Zellen per Drag-and-Drop verschoben (siehe 2 in Abb. 7) und ihre Größe festgelegt werden.
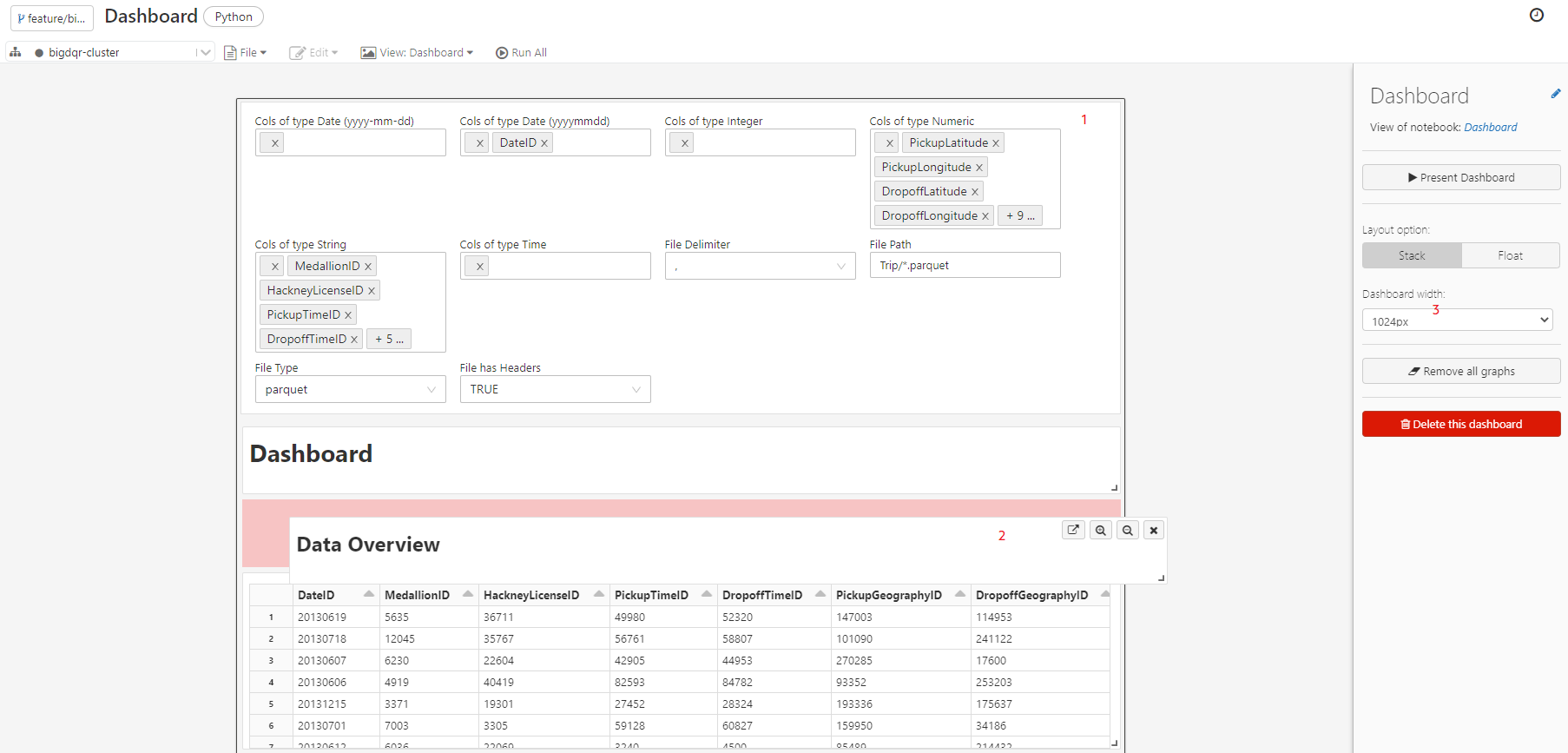
Abb. 7: Designen von Dashboards
Über das Zahnradsymbol über den Output-Zellen könnten Titel und andere Einstellungen konfiguriert werden (siehe 1 in Abb. 8). Das fertig erstellte Dashboard aktualisiert sich immer dann, wenn das Notebook durchläuft. Auch einzelne Grafiken können neu generiert werden, wenn der Run-Button angezeigt wird (siehe 2 in Abb. 8)
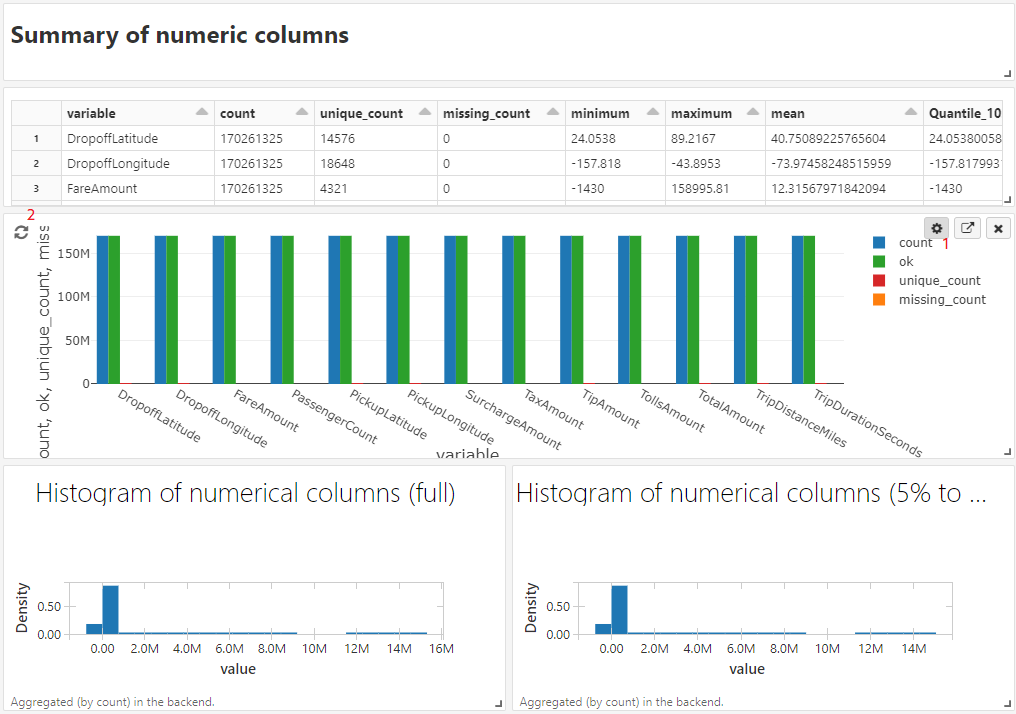
Abb. 8: Kalibrierung und Aktualisierung von Dashboards
Bereitstellen von Dashboards
Durch Klick auf “Present Dashboard” gelangt man in den Präsentationsmodus. Dieses Modul erlaubt die Präsentation des Dashboards ohne Möglichkeit der Bearbeitung des Designs. Dennoch kann interaktiv mit dem Notebook gearbeitet werden: Interaktive Grafiken sind nutzbar und das Dashboard kann durch Klick auf “Update” aktualisiert werden, etwa wenn die Parameter angepasst werden.
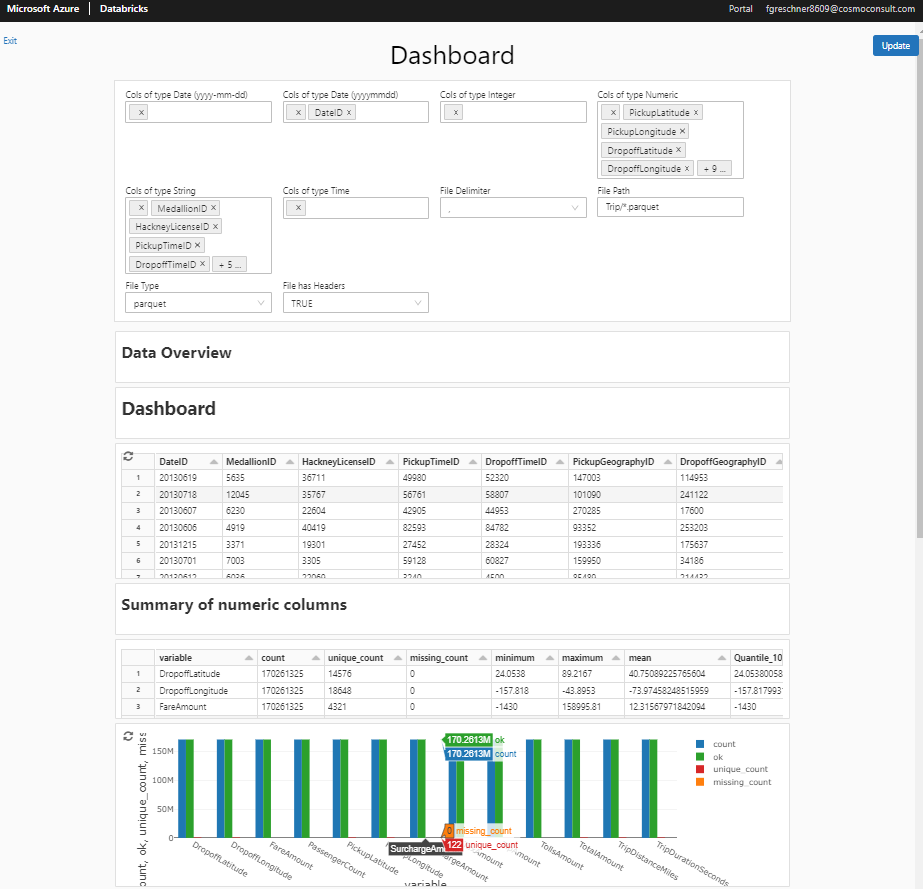
Abb. 9: Präsentationsmodus
Das Dashboard kann nun über einen Link jedem bereitgestellt werden, der auf den Databricks Zugriff besitzt. Die Zugriffsberechtigungen werden über die Admin Console gesteuert. Durch Scheduling kann das dem Dashboard zu Grunde liegende Notebook regelmäßig aktualisiert werden (siehe Abb. 10), um dem Key User stets ein aktuelles Dashboard zur Verfügung zu stellen.
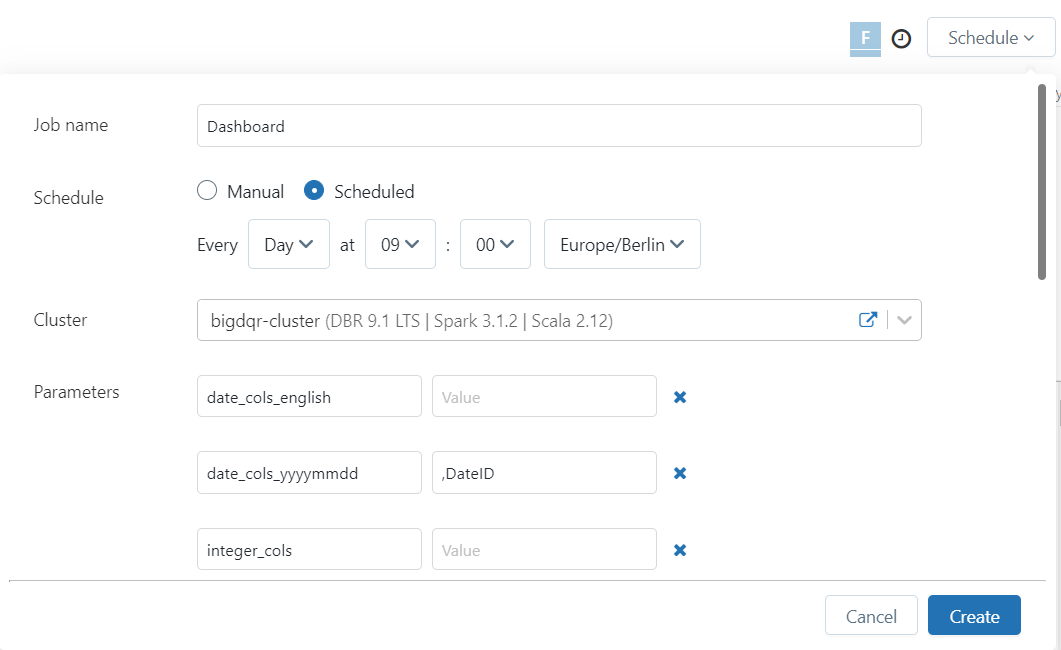
Abb. 10: Scheduling von Dashboards
Alternativ kann das Dashboard durch Export als html zur Verfügung gestellt werden (siehe 3 in Abb. 5). Auch dieses exportierte html-File ist interaktiv, wenngleich eine automatische Datenaktualisierung nicht möglich ist.
Grenzen und Nachteile
Bei all den Vorteilen des Dashboardings in Databricks sollen einige Nachteile nicht unerwähnt bleiben. Aktuell fehlt eine strukturierte Dashboardverwaltung, wie sie beispielsweise bei SQL-Dashboards in Databricks vorliegt. Aus diesem Grund können Dashboards, die von verschiedenen Personen entwickelt werden, nicht ohne weiteres gemeinsam bearbeitet werden. Des Weiteren ist die Verwaltung der Nutzer*innen kompliziert und führt hin und wieder zu Fehlern in der Zugangsberechtigung.
Zukünftig ist damit zu rechnen, dass Databricks diese Funktionalität noch deutlich ausbaut, sodass auch die oben angesprochenen Nachteile bald behoben sein dürften.
Fazit
Insgesamt wurde dargelegt, dass die Dashboards in Databricks durchaus eine performante und schnell umsetzbare Möglichkeit sind, um auch größte Datenmengen interaktiv zu visualisieren. Durch die Parametrisierbarkeit der Dashboards können diese sehr variabel gestaltet werden. Das Scheduling bietet eine Möglichkeit, die Dashboards regelmäßig zu aktualisieren, sodass, funktionierende Zugangsberechtigung vorausgesetzt, Databricks Dashboards zur regelmäßigen Überwachung und Darstellung von Daten gut eingesetzt werden können.
Möchten Sie mehr darüber erfahren, wie wir Databricks Dashboards in der Praxis anwenden? Wir freuen uns auf Ihre Anfrage über das Kontaktformular.