Reinforcement Learning: Mathematical framework (Part 2)
In a previous post we have given an non-formal introduction to Reinforcement Learning by means of an example. In what follows, we would like to consolidate some ideas and proceed with a more rigorous explanation about what actually Reinforcement Learning is.
In the Reinforcement Learning (RL) framework, the agent makes its decisions as a function of a signal from the environment called the environment’s state. Exploiting a property of the environment and its states, namely the Markov property, the mathematical formalism behind Reinforcement Learning can be described by Markov Decision Processes. To be more thorough, the Markov Decision Processes are the appropriate framework for RL problems with a fully observable environment (all relevant information about the environment are available to the agent).
The understanding of the theory behind Markov Decision Processes is an essential foundation for extending it to the more complex and realistic cases which don’t fit into the Markov formalism.
Markov Processes
A stochastic process is a family of random variables indexed by a set of numbers (called index set), which take values from a set called the state space. The index set does not need to be a countable set.
Markov processes are stochastic processes used to model systems that have a limited memory of their past. As an example, in population growth studies, the population growth of the next generation depends only on the present population and probably last few generations. A particular case is the first-order Markov process, which is a stochastic process with the conditional probability distribution of future states depending only upon the present state. This property of states is called Markov property.
Markov processes can be classified in:
- Discrete time processes (), also called Markov chains - e.g. Random walk, PageRank- the algorithm Google uses to prioritize the search results, games like go, chess, and many others
- Continuous time processes ( ) - e.g. Brownian motion, Birth-death process
In Markov processes one needs to define the transition mechanism between states, which is known in the literature as the Markov kernel. For the discrete-time case (Markov chains), the Markov kernel is known under a more familiar term, the transition matrix or stochastic matrix.
For our goal, that of describing the formalism for sequential decision making problems, the processes of interest are Markov chains.
Markov Chains
To keep the mathematical formulation simple, we concentrate further on Markov chains with a finite state space . This enables us to work with sums and probabilities rather than integrals and probability densities. However, the arguments can be easily extended to include continuous state spaces.
A stochastic process on has the Markov property if
Changing from state at time to at time is given by the transition probability:
In the above formula it is assumed that the transition probabilities do not change with time, they are time-homogeneous (which makes sense in many situations, think of a chess game, the rules of the game don’t change in time):
The transition matrix/stochastic matrix is
where are transition probabilities.
The th row of gives the distribution of the values of when and hence,
Example basketball game
Think of a basketball game with only 2 players played on one half of the basketball field and which finishes when one of the players scores first. There is no time limit and no abandon. It is possible to describe the evolution of one player (let’s say Player1) during such a game as a Markov chain with the following states: (has the ball outside 3-point line), (has the ball inside 3-point line), (the opponent has the ball), (Player1 scores), (the opponent scores). It is clear that for a basketball game in general, the Markov property is satisfied, since it is not important for what will happen next what were the previous movements before present situation. In this case there are two states which define the stopping of the game: and .
Now let’s assume that we have watched several games of Player1 against other opponents and we checked the situation of the games every 30 seconds. From the observations we could say that in of the situations the player starting behind the 3-point line remained there and in of the cases he managed to get close to the basket, in of the cases he has lost the ball behind the 3-point line, in other of the times he scored from the 3-point line and in of the cases he lost the game in a next move after being outside the 3-point line (this could mean that in 30 seconds time the opponent has stolen the ball and managed to score). These percentage values describe the probabilities of transitioning from state to every other state in the next time step (as mentioned, the time step is 30 seconds). In a similar way we could determine transition probabilities between every two states from the state space and get the following transition matrix:
For this Markov chain we have the following graph representation :
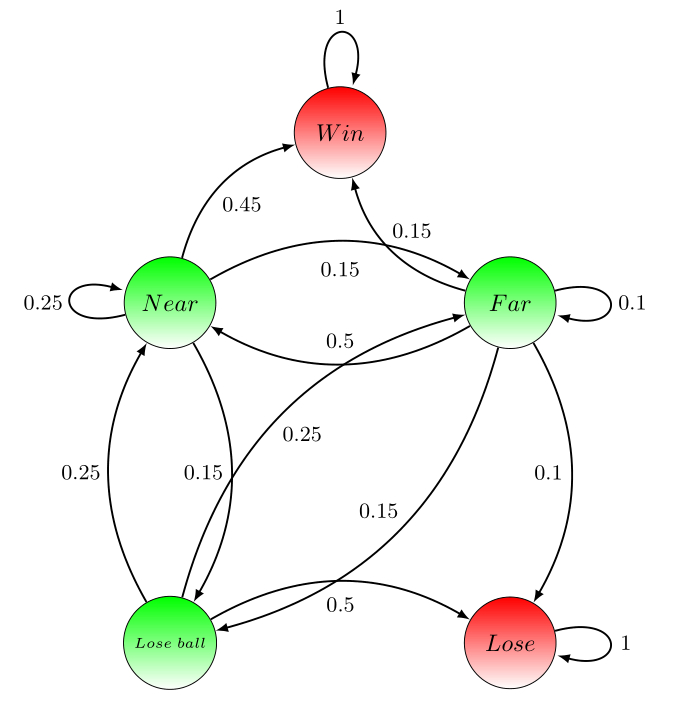
We can take some sample episodes starting in state and going through the Markov chain until we reach any of the terminal states or (which mark the end of the game):
- Sample: (the player is outside the 3-point line, moves inside the 3-point line, scores)
- Sample: (the player starts outside the 3-point line, moves inside the 3-point line, loses the ball and the opponent has to go outside the 3-point line, the player gets the ball back, comes near the basket, scores)
- Sample: (the player is outside the 3-point line, loses the ball, and the opponent scores)
If the state at the present time is , we could have some sample episodes like:
- Sample:
- Sample:
At this point the player jumps from state to state according the dynamic of the Markov chain, without knowing which state was good and which was bad. So what we do next is to hire a trainer which knows how good a certain situation is and stimulates the player to reach that situation (state).
Markov Reward Processes (MRP)
In a Markov chain there is no goal, just a jump from state to state according to the transition probability. Now we would like to go a step further with the formalism behind reinforcement learning and introduce the notion of reward, which is the most important ingredient needed to set goals.
Let’s consider a function which assigns to a state a real number called reward. At each time time step the reward value is denoted where is a Markov chain. Now, we define the expected reward function as the expected immediate reward from state :
The expected immediate reward tells us how good or bad it is to be in a state, or, how much reward is hoped to be made from the actual state at the next time step.
Markov chains equipped with expected reward function are called Markov reward processes. Formally, they are defined as the tuple with
- a finite countable set (state space)
- transition matrix defined in
- reward function defined in
- a discount factor
Example basketball game as MRP
For the basketball example we could associate to each state the following rewards:
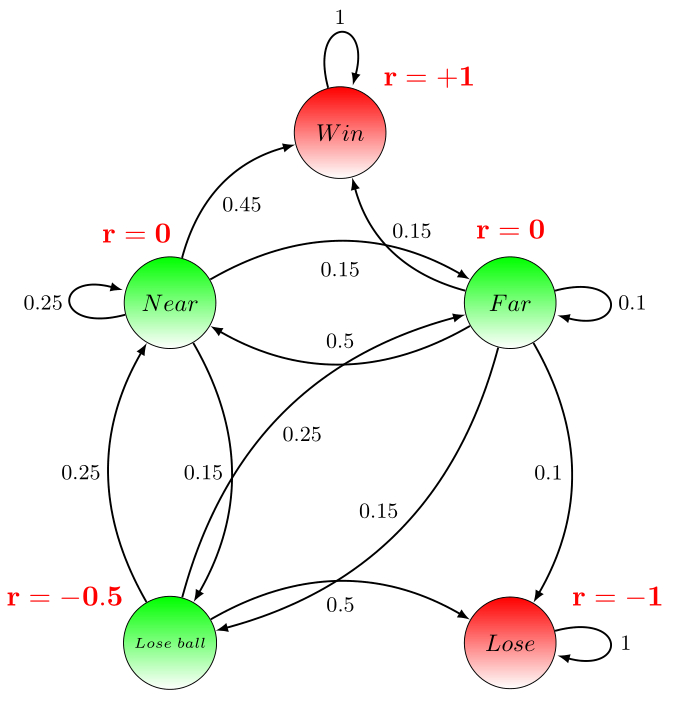
Let’s now denote the vector of rewards , then the corresponding expected reward (for making only one jump) for the given states can be obtained by multiplying the transition matrix with the reward vector :
In many applications it is not enough to consider only immediate expected rewards to decide how good or bad a state is to be in (e.g. in a chess game one has to go several steps in the future to see what is the potential of a certain state), but to take a cumulative reward on the long run, called the return. In fact the expected return is what we need, but first we will clarify how the return is defined.
Return
The return is defined as some function of the reward sequence and in the simplest case is the following sum:
where is a final time step. This notion of return makes sense in problems which can naturally be described in episodes (called episodic tasks), such as playing a game of chess. In such applications, the final state can be reached in a finite number of steps. What about when this is no longer the case? What is the situation of continuing tasks, applications which are not episodic, such as learning a certain theory from the internet (this could go on infinitely, there is no stop and start again from the beginning), or controlling a dynamical process? In these cases it no longer makes sense the above defined return, since the final time step would be and the sum could also be infinite(e.g. at each time step the reward is a positive number ). That is why, another return is introduced, the discounted return
where is the discount term.
Now, what is the idea behind this apparently complicated formulation? First of all it is important to notice that the above infinite series converges (has a finite sum) if the sequence of rewards is bounded (there exists a number such that ) and
where is the well-known geometric series.
It is clear that when the infinite series converges if and only if there exists a position such that for all . In other words, the definition of the return with makes sense for the finite case or for the infinite case with null reward from a certain time step further.
Another reason to use a discount term is to decide how important should future rewards be. For values of close to , the interest is in immediate rewards, whereas for close to also future rewards are taken more strongly into account. Humans have a preference for immediate rewards, but this is not always effective, take the example of a chess game where it is important to have a longer term strategy instead of following only to get maximum reward at each step (it makes sense sometimes even to give up on an important piece at some point having in mind a winning position after some steps).
The discount factor also accounts for the uncertainties in the future.
Example basketball game returns
For some sample episodes in our basketball example we compute the returns. Assume that we start in the state and take a discount factor , then we get:
- Sample:
- Sample:
- Sample:
Please notice that in the way we have defined the rewards for the basketball example, the process will not stop when first reaching “Win” or “Lose”, but will infinitely come back in these states. It is possible to make this example episodic, by introducing a so-called absorbing state (state with reward and probability to jump to itself) and give probability of transition from and to . In this way, after reaching one of the states or , the reward sequence wil continue infinitely with 0’s.
Value function
The measure for how good a state is on the long term is given by the value function. The Value function of a state is defined as the expected return starting from state
It is possible to rewrite the value function of a state at the present step as a sum of the expected immediate return and the value function of the succesor state
Bellman equation
This is in fact the Bellman equation for MRP and in the following we will show how to compute the value function of the states. Consider the state space then the Bellman equation
can be written in matrix form as:
If we denote and let and , then we have the following shorter notation:
which brings to
where is the identity matrix. The Bellman equation has a unique solution when When , the matrix is degenerated, since the transition matrix has as eigenvalue. In this case, there is no unique solution of the equation.
Solving the linear system is of order , where is the number of states, so direct solution is possible for small MRP. For large MRP there are different iterative approaches such as Dynamic Programming, Monte-Carlo evaluation, Temporal-Difference learning.
Example basketball game compute value function
By varying the discount factor in the interval , we display the evolution of the state values. One can see that the values of the states which show that Player1 is in control of the ball () increase as the discount factor increases and the other states, which have a negative reward () decrease as the discount factor increases. The curves for the state values increase/decrease exponentially (are unbounded) as goes to . However, by introducing the absorbing state (mentioned before), they will stabilize to a value.
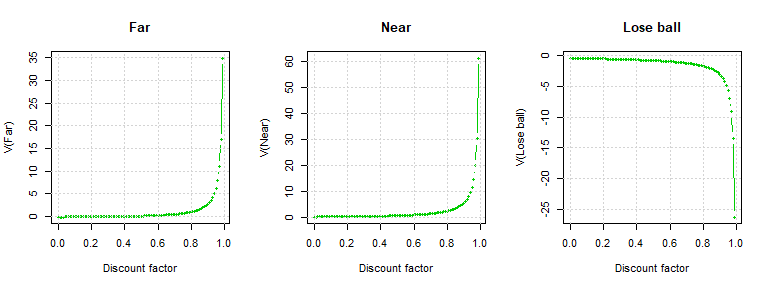
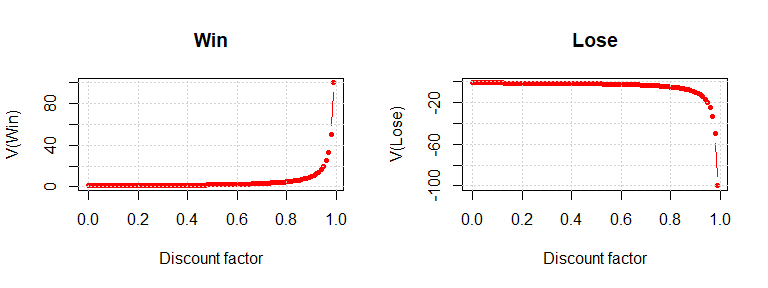
So far, the player has learned which situations could bring to a win and which to a lose, but he still cannot decide how to act in a game. Further, we want to give the player this possibility as well, and let him decide how to approach the game, hoping that the trainer showed him (by the value function) what he has to know in order to win a game.
Markov Decision Processes (MDP)
At each time step in a Markov chain over we have a reward . A Markov decision process is formally defined as the tuple with
- a finite set of states,
- a finite set of actions
- defined by the transition probabilities which gives the probability that taking action in state at moment will lead to state at moment .
- a reward function
is the expected immediate reward that the agent receives when changing from state by taking the action . - a discount factor ()
In the Markov reward processes we didn’t have any action, we had transition between states and values for the states in the form of rewards. By giving the player the chance to take a certain action when being in a state, the player will make a strategy for the game, called policy. His goal now will be to find the policy which helps him win, in mathematical formalism, the optimal policy.
Policy
A policy assigns to each state a probability distribution on the set of actions Once we have defined a policy , the Markov decision process becomes a Markov reward process with the state space For the basketball example this could mean that after having a strategy, the game developes as a sequence of states and associated actions.
In this setting (with fixed policy ), we have to specify how the transition mechanism between the states in the state space looks like. If at time step we are in , the transition at time to is given as:
The expected immediate reward for being in a state at time step is
Value Function
We can define the state-value function of an MDP as the expected return starting from state and following policy :
State-value function is a measure that tells us how good it is to be in state by further following policy .
The action-value function is the expected return starting from state , taking action , and following policy :
The action-value function tells us how good is it to take a certain action when being in a certain state.
The core problem of Markov decision processes is to find a policy for the agent, the one who makes the decisions. In fact, the goal is to find a policy which maximizes the state value function . For the basketball example, this means to find the best strategy for the game.
Define the pointwise maximum of by , i.e.
Similarly, the optimal action-value function is defined as
The function is called the optimal value function and it satisfies the Bellman optimality equation
The question we need to ask if there exists a policy such that ?
Theorem.
- There exists an optimal policy such that .
- Any such optimal policy also satisfies .
- There is always a deterministic policy which is optimal, satisfying
For the proof of the theorem we refer to the lecture notes of Ashwin Rao or the blog.
In general, the optimal policy is not uniquely determined, but we always find a deterministic policy by maximizing the action-value function. Finding an optimal policy involves solving the Bellman optimality equation, which is a non-linear equation and with no closed form in general. There are several numerical approaches for solving the Bellman optimality equation, such as Dynamic Programming methods (Value Iteration, Policy Iteration), or methods used for Temporal Difference Learning (like Q-learning and SARSA), which will be covered in our next blog.
References:
[1] Richard S. Sutton and Andrew G. Barto: Reinforcement Learning: An
Introduction, 2014
(https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf)
[2] David Silver: RL Course, 2013
(https://www.youtube.com/watch?v=2pWv7GOvuf0)
[3] Lex Fridman: Introduction to Reinforcement Learning
(https://www.youtube.com/watch?v=zR11FLZ-O9M)
[4] Ashwin Rao: Lecture notes (http://web.stanford.edu/class/cme241/lecture_slides/BellmanOperators.pdf)