Reinforcement Learning: Introduction (Part 1)
Recently I have become interested in Reinforcement Learning, a machine learning strategy that gained a lot of interest from the scientific community, as well as from almost everyone who is reading the news, mostly due to its success stories in real applications (see this). My intention is to make a series of discussions on this subject, trying to explain on the way my understanding and hoping that it could be of help to others. This first part is intended to give an intuition about what is going on in a Reinforcement Learning problem without getting into the mathematics involved.
Example
My 9 year old son wants to become a basketball player, so most weekends we go together to the playground and train by playing one-on-one games. This is a basketball game with only 2 players, played on one half of the basketball field and with no time limit. Each basket scored from near is one point and from the 3-point line is 2 points. The game is over when one of the players reaches 21 points, or when a player abandons. In these games I am the other player, and also the trainer.
When we started, my son knew the rules and some basics about how to dribble and how to throw at the basket, but he had no experience in playing against another player. So, the first games were a bit chaotic, he was running all over the field and throwing from where he had the chance. This did not bring much, since he became fast exhausted and had to abandon the game. Because he was concentrated only on running he was missing some good opportunities. So I started to encourage him when he performed a good move and pointed out the mistakes, such that he would avoid repeating them. This lead to a change in the irregular playing behavior and finally he managed to score a point, for which I congratulated him. He kept in mind the strategy that helped him to score a point, so he tried it again, and again, and at some point it didn’t bring anymore the expected results. My advice to him was that he should try something new, look for other positions or exploit new situations, in order to cover as much as possible from the situations that can appear in a game. In time, the games became more interesting, the actions more diverse and the final outcome of a game was more and more promising. More training, and thus, diverse situations and decisions, and constant feedback, have contributed to better final results of the games.
What is RL?
One day, I have seen my son playing with another boy, so I had in mind the following question: How could he improve his playing without having a trainer (someone that can specifically say what to do in certain situations) anymore? Could he look back and decipher those moments or elements which helped him become better, and which are they?
Further I will present a framework which can answer the above questions, and not only for the basketball problem but for a larger class, namely those problems in which someone/something must make a sequence of decisions in order to reach a final goal. The name of this framework is Reinforcement Learning and is a subfield of Artificial Intelligence. It offers the common language for sequential decision making problems and also the methods (recipes) how to successfully implement such a learning process.
Everything becomes easier now that we know in which formalism to fit our problem, because this means that there were people before us thinking how to solve them, so we could already try their attempts instead of starting from scratch.
Terminology
The central character of a RL problem is the agent, the learner of the process (a software program that can replace the basketball player in our example).
The agent can take actions in an environment which changes. Coming back to our example with the basketball game, one could imagine the environment as the basketball field with everything inside it. The agent’s information about the environment, what it observes at a moment of time is called state. Imagine that the basketball game is being filmed, then each frame of the video is a state of the environment in which the agent is acting (the position of the agent, position of the opponent, position of the ball, and other).
How does the agent move in the environment, or which are the possible actions? For the basketball example, the answer is the set of all possible moves and situations a player can experience on the basketball field (can move in any direction, jump, throw the ball, etc.).
Why would an agent act on the environment? Because there is a reward. The reward is a number used to decide how good or bad a certain state (or couple state-action) is. So, the reward will motivate the agent to search for good states, just like the basketball trainer was doing it with the player (“Well done”, “Not good enough”, “Change to the left side”, etc.). For the one-on-one basketball game a reward could look as follows: +2 if the agent scores from 3-point line, +1 if the agent scores from inside the 3-point line, -2 if the opponent scores from the 3-point line, -1 if the opponent scores from inside the 3-point line and 0 for the rest.
However, the reward determines the agent to take further actions following an immediate advantage, but does not have in mind the global goal of the process, and sometimes what is immediately good doesn’t mean that is also good on a longer term. Just think that the agent will always want to score from the 3-line points, because scoring from there will bring the biggest reward, but the agent is not good in throwing from such a distance. So, most likely that he will lose the game in front of an equally good opponent, but which also scores from near the basket. So how can the agent be made aware that there is a higher goal than only those immediate ones? Here comes in play the total reward (or value function), which is the cumulated reward that the agent expects to make from the present state on. The total reward depends on the strategy or policy that the agent uses, so for different strategies starting in the same state there are different total rewards. One policy for the basketball game could be that the agent throws the ball to the basket immediately he puts his hands on it. Another policy could be that the agent tries to get very close to the basket before he tries to score. Being somewhere outside the 3-point line it is clear that the expected outcomes of the two policies is different. For the first policy, the agent might waste the opportunity and lose the ball, whereas using the second policy there might be a chance to score and get a point.
How much immediate reward and how much global reward is optimal for the agent? This is decided by a number called discount factor, which balances the two rewards to help the agent achieve its goal.
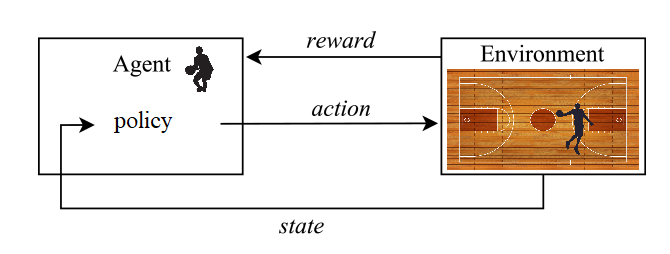
How does it work?
The ultimate goal of the RL agent is to find the best policy and this “best” is usually defined as the policy which maximizes the total reward.
Assume that our agent knows the rules of the one-on-one game, knows how to throw at the basket or how to dribble, but has never played a basketball game against another player. There is no trainer to tell him explicitly what to do, so how will he proceed? Without previous experience, the agent will start with a random policy, running all over the field, trying to score from any position. This is called trial-and-error.
Maybe our agent will not manage to score any points in the first game, so he will apply again something random in the hope for a weak spot of the opponent. After playing a longer time, the agent might manage to score, so his policy will be now updated with the information about the situation that brought it to score (because that was a good situation). And playing further might discover other favorable situations, with which the agent will update its policy. By performing many trial games, the agent gathers information and from information, experience. Hence, the experienced trainer is replaced now by the data gathered in the trials.
Let’s say that our agent played many games against the same player and now has to play against a new player. The policy learned might not help in this situation, so an important criteria for the success of such a learning process is the variety of the encountered situations. On an already known situation, the agent can decide not to use the usual approach which would bring for sure a reward, but to try something new, unexpected, which might bring more reward on the long run. This is called to balance the exploitation with the exploration. It can be the case when the agent is tired (low battery) and the best move is a fast attack, but this will exhaust him so hard that he might not be able to play further, so instead of doing that he can chose to take it slow, to take his breath (charge the battery) and to resist till the end of the game.
There are different methods to train an agent to find the best policy that brings it to its goal, but more about that and especially about their technicalities in Part2.
Please enjoy this video in which Reinforcement Learning was used to teach animated basketball players to acquire dribbling skills: Video made by CMUComputerScience
Conclusions
Like in the case of Neural Networks, which where influenced by the human brain, Reinforcement Learning was strongly influenced by the human learning process. Thus, it is only natural that a human learning process, such as learning to play basketball could be formulated with the help of RL-framework. The best part of Reinforcement Learning approach is that the rules are independent of the game one wishes to learn, what changes are the meaning behind the objects involved in the process (environment, policy, reward, etc.).
I hope that this description of a Reinforcement Learning problem and solution gave the reader some understanding about what kind of problems is Reinforcement Learning interested in and the topic and has increased the interest in finding more about this field. The next discussion will have a more mathematical approach, trying to describe the technical framework for formulating and solving such problems: Markov Decision Process, Bellman Equation.
References:
[1] Richard S. Sutton and Andrew G. Barto: Reinforcement Learning: An
Introduction, 2014
(https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf)
[2] David Silver: RL Course, 2013
(https://www.youtube.com/watch?v=2pWv7GOvuf0)
[3] Lex Fridman: Introduction to Reinforcement Learning
(https://www.youtube.com/watch?v=zR11FLZ-O9M)